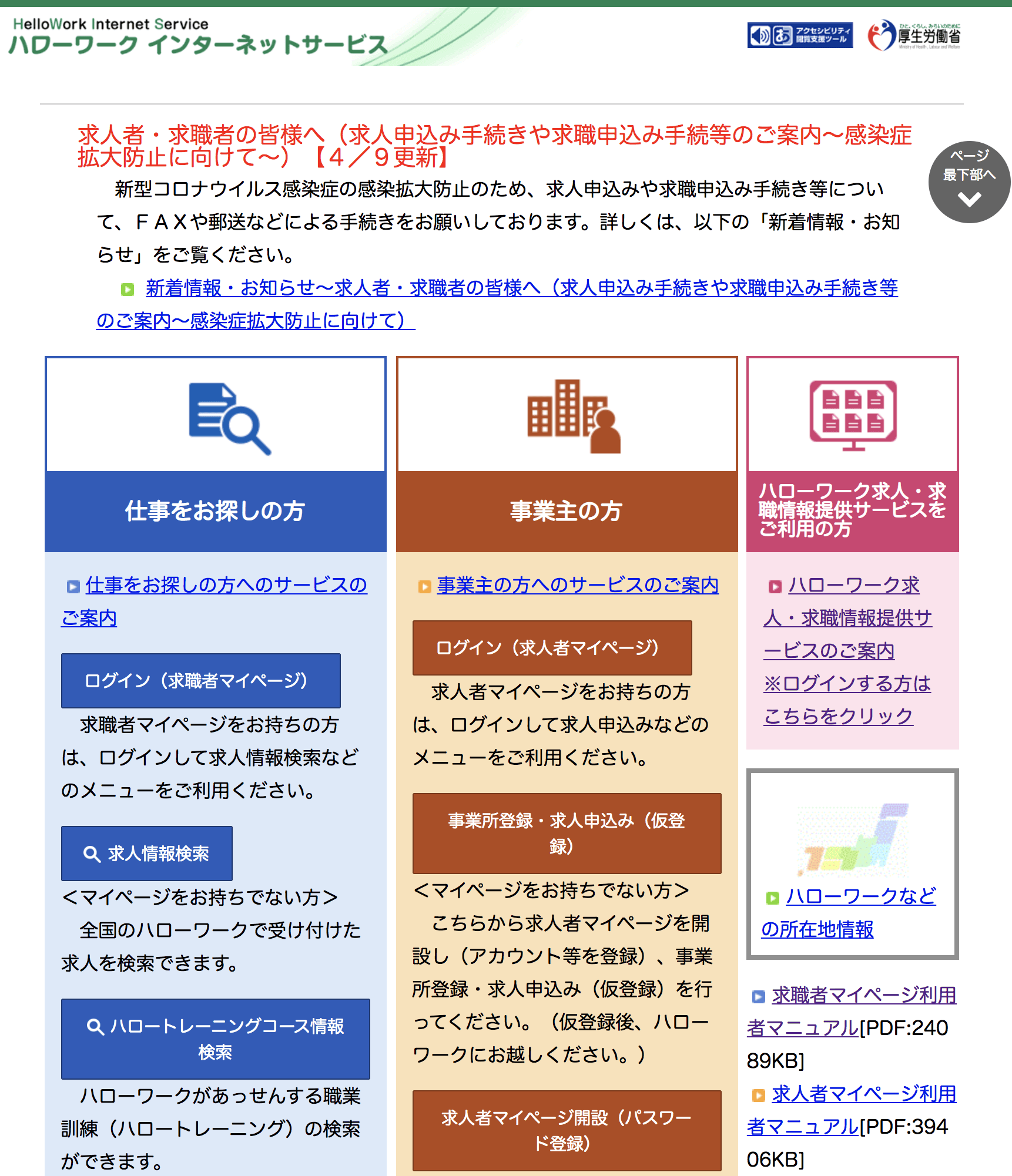
Python + Selenium + Beautiful Soupでハロワをスクレイピング
Python3でSelenium(ChromeDriver)とBeautiful Soupを使って、ハローワークの求人情報を取得する方法についてです。今回は東京都千代田区の求人情報を取得しようと思います。
実装方法
まず最初にライブラリを読み込みます。
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
from bs4 import BeautifulSoup
Chrome Driverを起動し、ハローワークのトップページにアクセスさせます。
url = "https://www.hellowork.mhlw.go.jp/"
driver = webdriver.Chrome()
driver.get(url)
time.sleep(1)
求人情報検索ボタンをクリックさせます。
driver.find_element_by_class_name("retrieval_icn").click()
time.sleep(1)
就業場所のセレクトボックスから東京都を選択させます。
element = driver.find_element_by_id("ID_tDFK1CmbBox")
Select(element).select_by_value("13")
time.sleep(1)
市区町村の選択ボタンをクリックします。
driver.find_element_by_id("ID_Btn").click()
time.sleep(1)
モーダルが起動したところで千代田区を選択させて決定ボタンをクリックさせます。
element = driver.find_element_by_id("ID_rank1CodeMulti")
Select(element).select_by_value("13101")
time.sleep(1)
driver.find_element_by_id("ID_ok").click()
time.sleep(1)
モーダルが閉じたところで検索ボタンをクリックさせます。
driver.find_element_by_id("ID_searchBtn").click()
time.sleep(1)
検索画面のHTMLをBeautiful Soupで解析します。
soup = BeautifulSoup(driver.page_source, "html.parser")
求人情報はkyujinというクラス名がついたテーブルで区切られているため、テーブルの情報を取得します。
jobs = soup.find_all("table", attrs={"class": "kyujin"})
今回は取得したテーブル情報からタイトルと待遇を抽出します。
message = ""
for i, job in enumerate(jobs):
job_name = str(job.find("td", attrs={"class": "m13"}).text.strip())
salary_tags = job.find_all("tr",attrs={"class": "border_new"})[5].select(".disp_inline_block")
for t, salary_tag in enumerate(salary_tags):
job_salary = salary_tag.text
message = message + "■{0} ( {1} ) \n".format(job_name, job_salary)
最後にこの結果を出力してブラウザを閉じます。
print(message)
driver.close()一連の実装まとめ
一連の実装をまとめると以下の通りとなります。
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
from bs4 import BeautifulSoup
url = "https://www.hellowork.mhlw.go.jp/"
driver = webdriver.Chrome()
driver.get(url)
time.sleep(1)
driver.find_element_by_class_name("retrieval_icn").click()
time.sleep(1)
element = driver.find_element_by_id("ID_tDFK1CmbBox")
Select(element).select_by_value("13")
time.sleep(1)
driver.find_element_by_id("ID_Btn").click()
time.sleep(1)
element = driver.find_element_by_id("ID_rank1CodeMulti")
Select(element).select_by_value("13101")
time.sleep(1)
driver.find_element_by_id("ID_ok").click()
time.sleep(1)
driver.find_element_by_id("ID_searchBtn").click()
time.sleep(1)
soup = BeautifulSoup(driver.page_source, "html.parser")
jobs = soup.find_all("table", attrs={"class": "kyujin"})[1::]
message = ""
for i, job in enumerate(jobs):
job_name = str(job.find("td", attrs={"class": "m13"}).text.strip())
salary_tags = job.find_all("tr",attrs={"class": "border_new"})[5].select(".disp_inline_block")
for t, salary_tag in enumerate(salary_tags):
job_salary = salary_tag.text
message = message + "■{0} ( {1} ) \n".format(job_name, job_salary)
print(message)
driver.close()
実行結果は以下の通りとなります。ハローワークの求人結果が取得できました。