このページについて
このページは、インプレスR&D『スクレイピング・ハッキング・ラボ』のサポートページです。『スクレイピング・ハッキング・ラボ』の疑問点や難しい点、正誤表、新しいHTMLへの対応などを記載していきます。

『スクレイピング・ハッキング・ラボ』についてわからない点がありましたら、Twitterなどで #スクレイピング・ハッキング・ラボ で投稿して頂けたら、対処法を調査していきます。是非ご活用ください。
しのさんの記事「スクレイピング・ハッキング・ラボ つまりポイントメモ」
しのさん(@drunker51)が「スクレイピング・ハッキング・ラボ つまりポイントメモ」という記事を書いてくださっています。2024年4月に書かれていて、『スクレイピング・ハッキング・ラボ』で使用しているライブラリが廃止されたり改名されたりした問題や英語環境での問題など詳細に対応策が書かれてあります。『スクレイピング・ハッキング・ラボ』で躓いた方は是非ご参照ください。しのさん、ありがとうございます。
第4章 文字列結合の誤記
「第4章 Python基礎」の「文字列を結合する」(紙版45ページ)で、出力結果を以下のように記述している箇所があります。
# Hellow World
正しくは以下となります。
# Hello World
第5章 スクレイピング結果に連番を採番する際にエラーが出る場合
「第5章 Beautiful Soupでスクレイピングする」の「スクレイピング結果に連番を採番する」(紙版68ページ)で、以下のエラーが出る場合があります。
AttributeError: 'str' object has no attribute 'find_all'
原因は、today変数がリスト型ではなく文字列型になっていることが原因です。この処理の前のブロックで以下が記述されています。
today = soup.find("div", attrs={"id": "on_this_day"}).text
この記述を以下のように修正すれば動作します。
today = soup.find("div", attrs={"id": "on_this_day"})
あるいは69ページのソースコードを記述する形でもかまいません。
第5章 Wikipediaから今日は何の日の年号をCSVで取得できない場合
「第5章 Beautiful Soupでスクレイピングする」の「スクレイピング結果をCSVに保存する」(紙版74ページ)で、日によって複数の丸括弧が使われている場合に対応できないケースがありました。紙版74ページで、以下のように記述されている箇所があります。
match=re.search("\((.*?)年\)",today_text)
この記述を以下のように修正します。
match = re.search("\(([1-9].*?)年\)", today_text)
これによりWikipediaの今日は何の日で複数の丸括弧が使われていても正常取得できるようになります。
第6章 robots.txt取得の誤記
「第6章 スクレイピングのテクニックと考慮すべき点」のrobots.txtの取得で、1行ずつ処理を解説している箇所(紙版90ページ)に以下のように記述していました。
robots.agent("*")
正しくは以下の記述となります。
agent = robots.agent("*")
また、同じページで、以下のように記述している箇所がありました。
agent = agent.allowed("https://allabout.co.jp/r_finance/")
正しくは以下の記述となります。
agent.allowed("https://allabout.co.jp/r_finance/")
この2箇所を修正することで正常に動作します。1行ずつ解説している箇所の誤記で、ソースコード全体を掲載している箇所ではこの記述になっており、正常に動作いたします。
第6章 プロキシサーバー構築でエラーが出た場合
「第6章 スクレイピングのテクニックと考慮すべき点」のプロキシサーバーの利用(紙版108ページ)で、プロキシサーバーを構築すると以下のエラーが出る場合があります。
curl: (56) Received HTTP code 403 from proxy after CONNECT
このエラーの原因としては、Squidインストール時の/etc/squid/squid.confの以下の記述が影響している可能性があります。
http_access deny all
その場合、/etc/squid/squid.confを編集して、Squidインストール時に記載されたhttp_access deny allをコメントアウトすると正常動作します。コメントアウト後に、本書の「#自分のグローバルIPアドレスだけを接続許可」以下のconf設定は必ず設定するようにしてください。
第11章 ghp-importインストールの誤記
「第11章 スクレイピング結果を自動通知する」の「11.7 静的サイトジェネレーターを使ってHTMLに出力する」(紙版189ページ)で、ライブラリのインストールコマンドを以下のように記述している箇所がありました。
$ pip3 ghp-import
正しくは以下のコマンドになります。
$ pip3 install ghp-import
第11章 Pelicanのpelican-quickstartが起動できない場合
「第11章 スクレイピング結果を自動通知する」の「11.7 静的サイトジェネレーターを使ってHTMLに出力する」(紙版188ページ)で、環境によってpelican-quickstartコマンドが起動できない場合があるようです。このようなケースでは、ホームディレクトリの~/.local/binにパスを通すと正常に動作する場合があります。
bashを使っている場合は~/.bash_profile、zshを使用している場合は~/.zshrcに以下を記述します。
export PATH=~/.local/bin:$PATH
bashの場合、以下のコマンドでシェルの再読み込みを行います。
$ source ~/.bash_profile
zshの場合、以下のコマンドでシェルの再読み込みを行います。
$ source ~/.zshrc
これでpelican-quickstartが使用できるようになる場合があります。
第13章 pip3 install mariadbでエラーが出る
「第13章 Raspberry Piにポータブル・スクレイピング・ハッキング・ラボを構築する」の「PythonからMariaDBに接続する」(紙版252ページ)で、下記のコマンドを実行した際、環境によってエラーが出る場合があります。
$ pip3 install mariadb
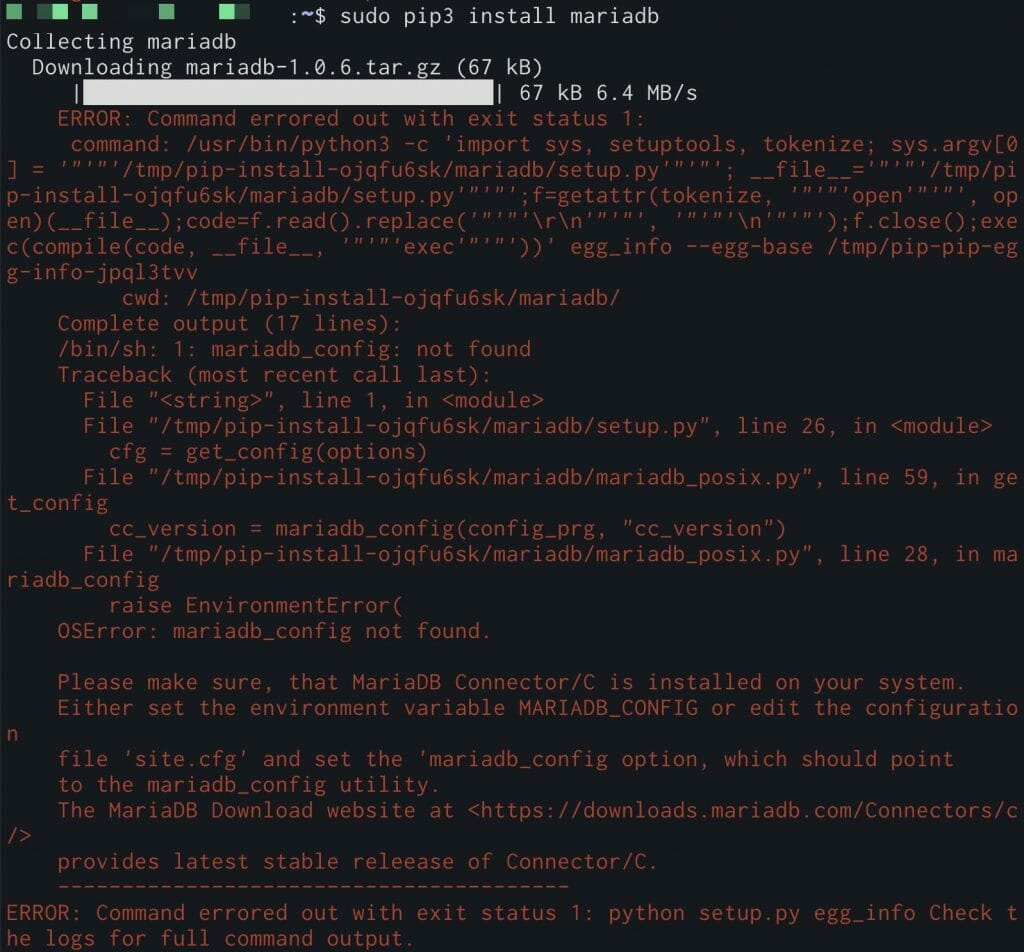
この場合、下記のコマンドを実行することでエラーが解消されます。
$ sudo apt install libmariadb-dev
第13章 はてなブックマークの人気エントリのデータを挿入する時にエラーが出るまたは反映されない
「第13章 Raspberry Piにポータブル・スクレイピング・ハッキング・ラボを構築する」の「はてなブックマークの人気エントリのデータを挿入する」(紙版258ページ)で、プログラムを実行した場合に、以下のエラーが出る場合があります。

プログラムの最後から2行目に以下のように書かれている箇所があります。
sql = "INSERT INTO entries ( 'title', 'bookmark', 'url', 'created_at') values( %s , %s, %s, %s)"
ここを以下のように修正するとエラーなく実行できます。
sql = "INSERT INTO entries ( `title`, `bookmark`, `url`, `created_at`) values( %s , %s, %s, %s)"
また、はてなブックマークのデータが反映されない場合があります。その場合、cursor.execute()の後にconn.commit()を実行すると反映される場合があります。
cursor.execute(sql, ( entry_title, bookmark, entry_url, created_at))
conn.commit() #追加